在分類模型中除了邏輯斯迴歸以外,另一個常見的模型為樹模型(tree-based model),常見的有決策樹、迴歸樹,樹模型的優點是模型好解釋、模型訓練速度快,缺點是預測能力較不穩定、模型會受到不平衡資料影響。
迴歸樹與決策樹的差別在於:迴歸樹的輸出結果可能是實數,而決策樹的輸出結果為離散型
以下使用R語言內建資料集iris,來建立CART決策樹模型,一樣先將資料分成訓練集和測試集,確保模型準確率的可信度。
# 載入模型套件
library(rpart)
library(rpart.plot)
library(caTools)
split <- sample.split(iris, SplitRatio = 0.8)
train_data <- subset(iris, split == "TRUE")
test_data <- subset(iris, split == "FALSE")
使用rpart()建立模型,rpart.control()中有一些參數可以針對模型做調整,如: maxdepth代表樹的深度,cp決定計算複雜度,模型建立後,可用printcp()函數來看不同cp下的相對誤差,用來決定cp要是多少
model <- rpart(Species~Petal.Length+Petal.Width+Sepal.Width+Sepal.Length,
data=train_data,
control=rpart.control(maxdepth=3),
method ="class”)
printcp(x = model)
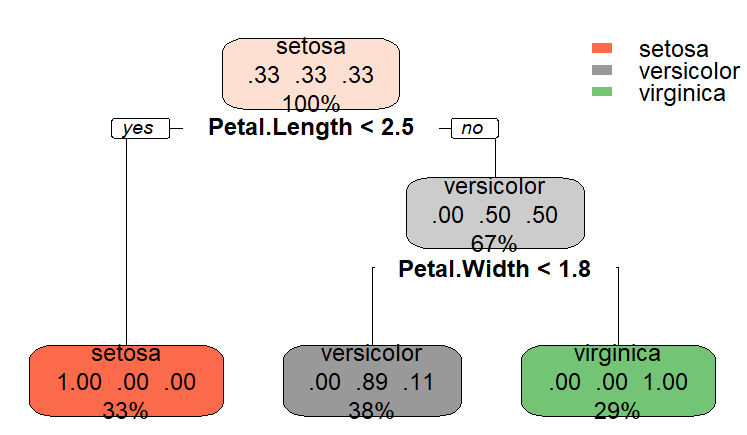
使用rpart.plot()來將模型結果視覺化,越上層的變數代表越重要
rpart.plot(model)
最後,使用測試集來做預測,並查看模型結果,由下表可以看出在預測集中只有誤判一筆(斜對角數字為判斷正確)
result = predict(model,newdata = test_data, type="class")
table(truth=testing_data$Species, result)
result
truth setosa versicolor virginica
setosa 10 0 0
versicolor 0 9 1
virginica 0 0 10

